- Published on
The Zephyr VM: core of the Mercury code execution environment.
- Authors
- Name
- Tommaso
- @heytdep
Introduction
If you've taken a deep look at Mercury and its proposal document, or followed our Stellar Stage pitch, you'll already know that we plan on Mercury having a so-called "code execution environment".
But let's take it a small step back for those who are new here.
Mercury is the data indexer we're actively building thanks to the Stellar Community Fund. Without going off-topic and getting into a more detailed explanation, Mercury is a centralized service that allows users to subscribe to and index Stellar/Soroban data cheaply and efficiently.
One of the pillars of Mercury is simplicity and as little setup as possible/no setup. In fact, as of now our ingestor only writes to our database and Mercury can't run on anywhere that is not our server. Don't get us wrong, we love open source (in fact, crates we are writing on which Mercury relies are open source and implementation-agnostic) but it's also essential to have alternatives that don't require setting up an infrastructure. Also, indexed data is verifiable through Stellar Archives and thus one can easily conduct audits on the integrity of our data.
A code execution environment ... on an indexer?
So, why are we talking about a code execution environment for Mercury?
The answer is that we aim to empower users with cloud execution that operates in symbiosis with the Stellar network and can interact with the Mercury database locally.
This means that when Mercury's code execution environment goes live you'll be able to deploy to cloud small applications that run for every new ledger close with access to the whole ledger metadata. These programs are also able to read and write Mercury's database safely.
Now that you have a bit more context, let's dive a bit deeper into this concept, how it works, and what use cases it has.
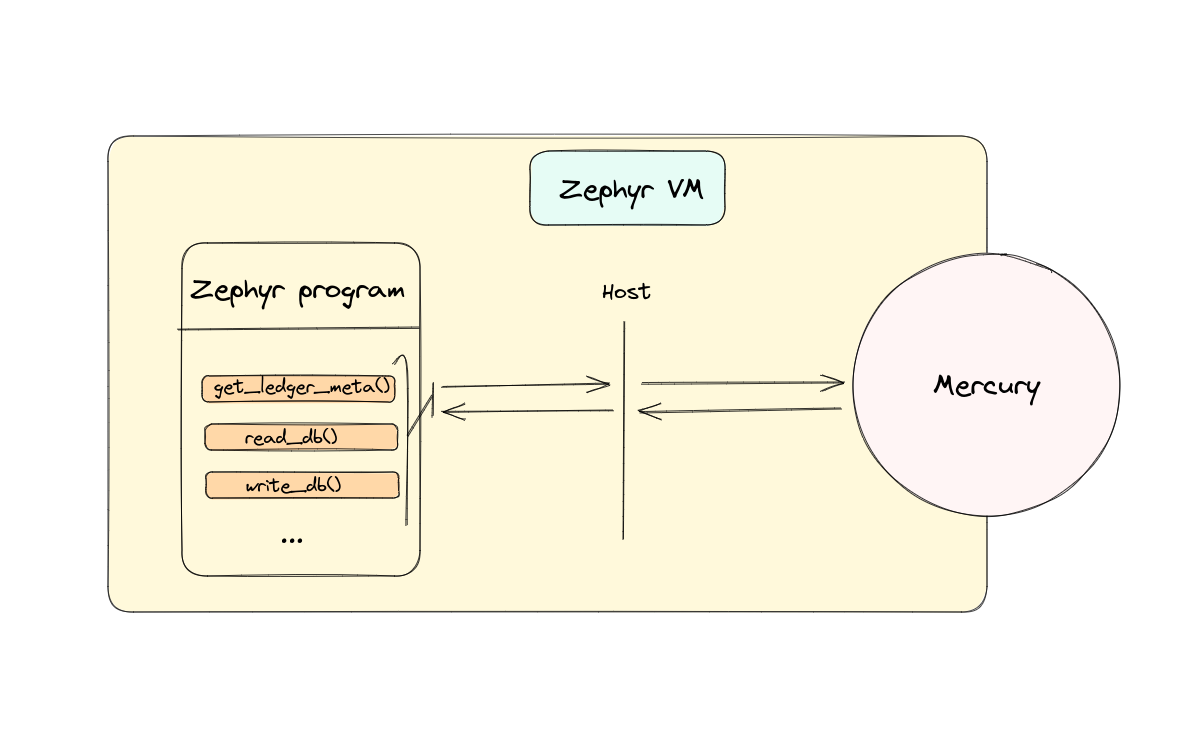
The Zephyr VM
At xyclooLabs we just recently started developing Zephyr, hence the choice of writing and publishing this post now instead of a month ago: we now have a clear direction to go towards and development is going pretty fast.
Anyways, the Zephyr VM is being built on top of WebAssembly (WASM).
The Zephyr Virtual Machine executes WASM modules and provides them with bindings for accessing the Network's data held in Mercury's database and the ledgers meta. The choice of using WebAssembly is due to several factors:
- Development. Building on WebAssembly allows us to rely on a thriving ecosystem with a proven efficient and safe execution.
- Safety. Developing on Rust, and executing programs in a WebAssembly Virtual Machine allows us to run the programs in a safe environment for both users and our infrastructure.
- Efficiency and Metering. Programs running on Zephyr will be very simple, even simpler than a smart contract. WebAssembly's design and its ergonomic host environment integration with the guest environment seem like a perfect match. Additionally, a WebAssembly environment offers extensive possibilities in terms of metering each execution, which fits perfectly a use case like Zephyr, or more broadly speaking Mercury, where users pay exactly for what they consume.
Now, why would someone want to run programs on Zephyr? What possibilities does it introduce in Mercury?
Why Mercury + Zephyr
We believe that Zephyr's integration in Mercury can create lots of value for the ecosystem. Mercury allows anyone to build specialized services that rely on the network's data without needing any form of setup or infrastructure. It will also generally be cheaper for the implementors to run their programs on Mercury rather than running their own instance!
These programs can be anything ranging from protocol-centered services (for example a team monitoring their DeFi protocol) to user-centered services (like advanced alerts for traders).
We came up with some example applications for the Mercury + Zephyr integration:
Advanced alert systems. Traders and arbitrageurs often need to be synced with the Network's activity and keep track of many assets at the same time, their liquidity, frequency of certain actions in a interval, and so on. Zephyr allows to communicate with the external world through particular host functions, empowering traders and arbitrageurs to build highly customized alert and trading strategies on top of Mercury + Zephyr without having to step into the challenges of managing a database and running an instance.
Trackers. Sometimes, we need to be able to track exactly where some funds are being held and where they're being moved (and track the funds on the other ). Zephyr makes this kind of watcher services easy to create and efficient to run.
Multi-step workflows. This also in some way encompasses most applications of Zephyr, but it's worth mentioning as its own utility category. Zephyr enables users to create workflows where each step depends on the result of the previous one, facilitating complex processes.
Highly customized indexing. Some users might require very specific querying capabilities/database structures that wouldn't make sense to have in the default database structure. In such cases, Zephyr allows them to write their own ingestion mechanisms. We are also evaluating how feasible the implementation of custom queries is.
User-defined data aggregations. Through Zephyr, users can define personalized aggregation functions and calculations for their unique requirements. For example, a Zephyr program could track on a per-ledger basis which are the best swap paths across various pools and protocols (both Soroban and Stellar Classic!).
On-the-fly subscriptions. We plan to also support a mechanism where Zephyr can dynamically create subscriptions for the user for certain data. For example, this might be critical in cases where the implementor wants to track all contracts with a specific code, and then monitor for deployments of those contracts and dynamically create/modify their Mercury subscriptions to also store and index data for these contracts.
Custom data retention policies. In Mercury, users pay for the amount of data they use, Zephyr empowers users to discard stored and indexed data following custom policies to cut costs in the long run.
Protocol health checks. Part of maintaining a protocol (and sometimes even auditing one) is to monitor that the protocol is working exactly as expected. Even if blockchain is built on determinism and Soroban has some pretty sick testing capabilities, monitoring that contracts are working as expected is important, especially for complex protocols that might also have actions that are bound but happen in different ledgers. Mercury + Zephyr stands as an easy-to-spin-up way to deploy this kind of watcher program.
Note: Depending on the implementor's logic, some of these applications may also require a very simple callback backend.
These are the major use cases we've thought of for now, but the possibilities are endless given the very nature of the host environment.
Also, to tackle the scalability and costs of running the programs for every ledger, we're exploring implementations of conditional triggering. For instance, say your Zephyr program is only pertinent when a specific contract is invoked, or when a certain operation is performed, you can specify such conditions to Mercury, which will execute the program if these are met.
This will prevent your code from being run for every ledger close, scaling better on our end, and saving costs on the user's end.
Implementation
In the following weeks, we aim to release more content around the implementation itself. The implementation itself is nontrivial but neither too complex, the challenges arise when dealing with execution metering, constraints, and efficient memory management and sharing. But as this is targeted to be a post that introduces the ecosystem to Mercury + Zephyr, we want to focus more on how we imagine the implementation would work client-side, i.e. how we are imagining users writing programs for Zephyr.
SDKs
To write Zephyr-compatible programs in an ergonomic way we're committed to building SDKs that facilitate communicating with the host environment. The first SDK will surely be for Rust, but we would like to build SDKs also for other languages (our second favorite choice is Zig, but it would likely mean having to spend resources to work with XDR efficiently in a language that doesn't have a stellar XDR library yet).
Anyways, this is how we envision the first SDK release candidate might look like:
Note: Please note that our SDK implementation is currently almost non-existent, for the stage we are in development we're mostly writing WAT code. Thus, the actual SDK implementation will likely be very different from the example we're showing here.
use zephyr_sdk::{Database, EnvClient, FilterInstrs, xdr};
pub fn on_close() {
let env = EnvClient::new();
let db = Database::new(&env);
let tx_processing = env.get_close().tx_processing();
for tx_meta in tx_processing {
// ... do some stuff
}
if certain_condition {
// read from Mercury's database by structuring a query:
// - read point (in Mercury, so SQL, the table name).
// - what to read (in Mercury, so SQL, the columns to read).
// - filtering.
let rows = db.read(
"table_name",
&["column1", "column2"],
Some(&[
FilterInstrs::Symbol("column1"),
FilterInstrs::Gt,
FilterInstrs::Int(5000)
]) // The following option adds a filter so that values in
// `column1` > 5000.
);
// the above query in Mercury's Zephyr implementation effectively resolves
// to [`SELECT column1, column2 FROM table_name WHERE column1 > 5000`]
}
if other_condition {
// write to user's private table hash(table_name + user id).
db.write_priv("table_name", &["column1"], &[200]);
}
}
Is Zephyr Open Source? Implementation agnostic?
Some of you might be wondering whether Zephyr will be open-source or not. On this point, there are a couple of considerations.
First of all, Zephyr is being built implementation-agnostic. This means that while built for being integrated into Mercury, it doesn't care if it's Mercury implementing the host: as long as the implementation-specific traits are implemented, Zephyr can run anywhere.
We can't make any promises since there are still some considerations to be done on this topic, but Zephyr will likely be open source. However, for now, given the stage we are in development, the codebase remains private.
Conclusion
We're quite excited to see what Zephyr is capable of when integrated on Mercury. We plan for the second beta release candidate to implement the first (maybe not feature-complete yet) version of Mercury + Zephyr, so stay tuned!.
Also, this is our first blog post, so welcome to the xyclooLabs blog, and thanks for reading!